
Journal of Law, Information and Science

|
|
Home
| Databases
| WorldLII
| Search
| Feedback
Journal of Law, Information and Science |
|
by Jon Bing[*]
This article examines three likely directions for the future development of Computers and Law and Computer Law. The first is the growing emphasis on the interrelationship between knowledge based systems and legal philosophy or jurisprudence, a topic which has been and continues to be debated in this Journal by Moles, Hunter, Tyree, Zeleznikow and others. The second development is an educational one--the need for universities to design curricula which take into account, more than they do now, developments in information science and law. This is especially true for the area of public administration. Finally, the article discusses the need for impact studies to assess the impact upon society of new information technology.
___________________________
When it started, it seemed like an obvious thing that the emerging field of research, informally known as "computers and law" included both legal information technology and the law of information and technology. Today, this combination may seem less than obvious. It is to some extent an unholy marriage: The monster of Dr. Victor Frankenstein representing the knowledge based technology of which the monster actually is an early symbol; The bride is the Lady Justitia in her blue dress and red robe, carrying the balance and sword, the traditional symbols of social justice and punishment.
Today, when the area of "computers and law" has become large and diversified, researchers will specialise rather than become "computers and law" generalists. And to these specialised colleagues, it may be difficult to explain why there is a tradition for combining the two aspects of legal information technology and the law of information technology.
We shall avoid tracing the development of computers and law. It may be worth noting, however, that there would seem to be a slight difference between European and North-American origins.
For instance, in the United States, different persons pioneered the two different aspects - John F Horty created the first successful text retrieval system in 1960, of a design very similar to that of today's systems. While persons like Roy N Freed[2] and Robert Bigelow[3] started to develop the area of information technology law.
In Europe, some of first persons combined interest in both areas. This is true for Lucien Mehl, who wrote in 1960, we believe, the first paper on computers and law in Europe,[4] and also for Colin Tapper, who brought an academic flavour into the field.[5] It is also true for some of the first institutions to be created at the end of the 1960's. The two oldest are probably the French IRETIJ[6] founded by Pierre Catala,[7] and the Swedish Legal Informatics Research Institute (Stockholm) founded by Peter Seipel - both institutions are still concerned with the double aspect of computers and law.[8] One may cite Canadian examples of this double role, like Stephen Skelly and Richard Morgan[9] or, a focal point of many Europeans, Professor Ejan Mackaay.[10]
It would be too facile to maintain that this is incidental. But it should be appreciated that the technology was far less accessible in those days. Mastering the basics of computer science qualified you both to sketch possible technological developments for lawyers, mainly for information retrieval, and to discuss the legal problems accentuated by the technology - a list of issues containing data protection, computer contracts, and legal protection of programs, issues somewhat unrelated apart from their common cause in the technological developments.
Peter Seipel has in his pioneering doctorate thesis[11] maintained that there is a substantial relationship within the two areas that make them fuse together into one discipline. One does not have to accept that view without reservation to realise that there must be more than an incidental relation between the two areas. The common origin must be explained by something apart from the fascination of a new and dazzling technology by men who at that time were quite young.
It would be tempting to divulge in the past and further nostalgic memories. The history of our field of research is still to be written, and those very first pioneers of computers and law are still with us as first hand sources to the developments. But our discussion today is to take us into the future of this dual field rather than to dwell on the past. We will therefore limit this introduction to two examples of the intimate relationship between computer law and computers.
One is the relation between data protection law and computer science. In Norwegian law, one of the basic concepts is that of a personal data system, a "register". This term is typical for the first generation data protection legislation, and an attempt to find a technological neutral way of qualifying which collections of personal data should be subject to the provisions of the law. National definitions vary, in Norway - like in the US Data Protection Act of 1973 - retrievability is the major criterion. In explaining retrievability, it is very useful that the students also have background in text retrieval, and understand how to retrieve a document by using a term - or a combination of terms - from the authentic text. Even in this basic way it is obvious that it is necessary for discussions of data protection law to have an understanding of computer science which includes data organisation and other elements of data base design.
The other is the teaching of copyright protection of computer programs and data bases. For instance, in discussing what is a "copy" in the terms of copyright law, one has to distinguish between the volatile representations of a work in a CPU and the more permanent ones on a hard disk. It becomes necessary to discuss the relation between object and source code to explain the new provisions flowing from the directive of the Commission of the European Communities on decompilation, which also presumes some knowledge of a compiler. Or to argue that the display of program code on the screen of a work station is the performance and not the exhibition of a text, something our own natural language makes less obvious than English. Actually, one may use the background knowledge of intellectual property law as a vehicle to explain computer technology, making distinctions which may be unfamiliar to the computer scientist, but meaningful to a lawyer.
This interdependence represents, I believe, one of the more exiting aspects of the field of computers and law. I will therefore go on to discuss one area in which I think there is considerable synergy effect, that is the emerging field of knowledge based technology and law, or - as it is commonly known - AI and law and its possibilities for legal philosophy or jurisprudence.
I will continue by discussing some aspects of the new proposed Masters program in Norway for "informatics in administration", and close by returning to the issue of whether there is actually an "information law".
Within the area of knowledge based systems and law, at least two competing general approaches to modelling law can be discerned.
One is called case based reasoning. It concerns itself with cases and identifying a precedent for a current problem which may indicate the solution of that problem. But this is not the reason for its name, rather it is "case based because the experience is recorded not necessarily in generalised rules but in discrete, specific historical casts." This is how Kevin D. Ashley qualifies the nature of case based reasoning, and I will use his well-documentated system as an example in the following.[12]
One may be fascinated by knowledge based systems for different reasons. One reason is that computerised models of legal argument offer a very specific formalism with a clear and certain semantic. One may in the practical notation of programming languages specify a certain theory of legal rules, and make this available to inspection. Because programming languages are flexible and contain numerous possibilities, while retaining their certain semantics, they are languages of many nuances in which to describe different views, for instance of legal rules. This may lure somebody interested in legal philosophy or jurisprudence to pay attention to information technology, and see the design of knowledge based systems as arguments in a continuous debate on normative theory rather than as attempts to construct high technology merchandise as marketable expert systems etc.
In the work at the Norwegian Research Centre for Computers and Law we have emphasised two rather specialised aspects. One is the representation of legal uncertainty or legal expert judgements. The other is the possible necessity to include modal logic in the representation of legal knowledge.
This brings us back to case reasoning and the identification of precedents. The citation of Ashley emphasises a certain distinction between rule based and case based reasoning. One may see that this view roughly also is the distinction between those using PORLOG-like programming languages and those using LISP-derivation, and also between Europe and North-America.
At a number of occasions I have been struck by my own difficulty of grasping the real difference - in legal terms - between rule based and case based reasoning. It occurred to me that this might be explained by my national prejudices in the theory of interpreting cases. It may be that the preference for case based or rule based reasoning as a basis for modelling legal argument may be related to case law or civil law jurisdictions. For a jurisdiction relying heavily on case law and the doctrine of stare decisis, case based reasoning may seem appropriate. For a jurisdiction relying on statutory authority and citations, rule based reasoning may be a more obvious alternative. As Norway is neither a common law nor civil law jurisdiction, we have, perhaps, not had to make a real choice.
For there are different theories on the interpretation of cases, of course. One theory (which is known as direct or parallel comparison) insists that the fact situation of the current case is directly compared to previous cases with respect to common features. If the similarity is sufficient, the previous case is a precedent and constitutes an argument for solving the problem represented by the current case in the same way. The strength of the argument relies in my native jurisdiction on the degree of similarity. In a jurisdiction governed by the stare decisis doctrine there might be a duty to follow the precedent.
The other major theory (comparison by generalisation) presumes that any prior case is based on some, perhaps unspecified, more general rule. This rule is the bridge between the current and the previous cases which may be possible precedents. Similar to applying a statutory rule, the facts of the case are compared with the criteria of the rule, which is applied if there is a match - something which may be open to argument.
The common view within my jurisdiction is that these two ways of looking at the use of precedents actually are identical, and may be mapped into each other - the "qualified similarity" of the direct comparison has to be measured one way or the other, and the measure may be seen as the rule suggested in the comparison by generalisation.
This makes reasoning on the basis of precedents also rule based reasoning. The crucial point may be that the rules for comparing cases, though clearly examples of legal rules, are somewhat more complex that the more trivial if ... then-rules of statutory prose. It was suggested in Norwegian legal theory that they could be seen as legal expert judgements.[13] Such rules have a set of triadic sub-rules, each sub-rule (1) having a criterion qualifying which facts or circumstances of a case would trigger the rule, (2) having a value determining which of the possible alternative results of the expert judgement and the sub-rule was favouring, and (3) having a relative weight indicating the strength of the sub-rules favour with respect to the specified result.
This basic structure is rather simple, and may easily be translated into a computerised model. The theory is somewhat more complex. Especially important was the claim that expert judgements governed by such sets of sub-rules was non-deterministic, one could not in advance specify all the facts or circumstances which possibly could be relevant with respect to a certain decision, nor the relative weights in a certain case. But in our context, it is just the notion and texture of these expert judgements which is the point.
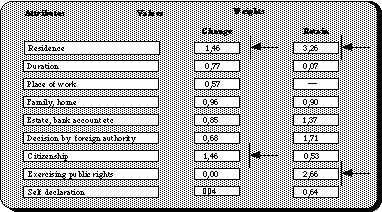
As an example is offered a model based on analysis of the small number of court decisions with respect to international domicile in Norwegian law, a concept that his understood similarly in the corresponding concept in English law. The cases have been described and analysed according to a model developed at the Norwegian Research Centre for Computers and Law allowing analysis according to a model based on the legal theory mentioned above, SARA.[14] In the diagram, the attributes are those circumstances that the courts seem to find of relevance in deciding the case. There are two possible results, either the court decides that domicile has been changed (either losing Norwegian domicile, or achieving Norwegian domicile, depending on what may be the situation), or domicile is retained (with the corresponding two alternatives). For each attribute-value combination, relative weights are calculated with allows the system to explain the maximum number of cases described. The two combinations with highest weights are indicated.
This example is offered for illustration's, not as an attempt to discuss the Norwegian interlegal concept of domicile.
These legal expert judgements were suggested as a means for explaining the structure of the rule bridging the gap between a current case and a precedent, and therefore an example of modelling rule based reasoning.
On the basis of this possibility, one may return to the example of Ashley's system. One will find that the comparison between a current case and precedents is made by using so called "dimensions". They may be understood as an encoding of the features of a case that have relevance for arguing the legal merits of a claim. For instance, in a claim for trade secret misappropriation, the dimension "competitive-advantage-gained" will strengthen a plaintiff's argument the greater the competitive advantage gained by the defendant. In order to apply, the current case must contain the fact "defendant saved product development expense relative to plaintiff".
Using the terminology already introduced, the dimension may be seen as a sub-rule in a legal expert judgement. The criterion for this sub-rule to fire, is the match on "competitive-advantage-gained". The dimension defines the value in favour of the plaintiff's argument. And the weight is set in a sophisticated way using "focal slots" which allow the weight to be influenced by a number of variables in the current case, like development time and cost for both the plaintiff's and defendant's products. The result is a corresponding triadic representation, though considerably richer in structure, using the "focal slot" as a way of allowing a more detailed representation of the attribute to determine the weights.
Fig 2- Dimensions and focal slots translated into a triadic representation
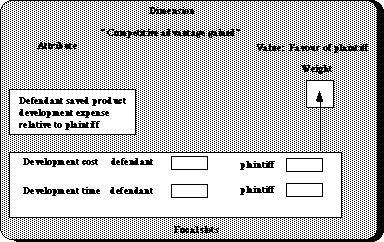
This is a comparison overly simplified. And the merit of Ashley's system and research is obviously not the fact that it is characterised as "case based reasoning", but the sophistication of the representation cases are the effectiveness of comparing a current case with prior and hypothetical cases. I will be forgiven, nevertheless, for emphasising my small, didactic point: When different terminologies are peeled away, a basic structure emerges which has strong similarities with the theory of legal norms developed in another part of the world by a traditional legal academic who at that time took no interest in computers.[15] The disclosed similarity is between a computerised case based model and a suggested explanation of comparison by generalisation, which is a rule based approach.
These similarities may be taken as an indication of a need for further clarification before we can conclude that direct comparison really is different from comparison by generalisation.
Perhaps it is our concept of a legal "rule" which has to be reformed, and perhaps the discussion we have mentioned, is related to open textured concepts and the legal principles of Dworkin.[16]
It is fascinating that a study of a detailed model for identifying precedents is related with our basic understanding of law, and possible differences in legal method or culture in different jurisdictions. And in this observation lies my point with respect to the future of the legal technology.
Information technology emerges as a paradigm for the discourse of legal method, legal philosophy, or jurisprudence. Stimulated by the new possibilities of encoding knowledge in the formalism of programming languages, and the practical benefits of automating some elements of legal decisions, our understanding of "the lawyering process" is enhanced and transformed. It is not so much a question of automating legal decision processes, as the synergy of an interaction between a new technology and the analysis of legal argument. As lawyers, we have been offered a new metaphor for our own methods - and as any appropriate metaphor, it may be employed to enlighten us.
I am confident that this will emerge as a lasting benefit for legal philosophy or jurisprudence. Basic and fundamental problems will again be discussed and analysed, and the paradigm of information technology will allow us a different approach than in the past, and new insights. I suspect that the legal philosopher of the near future who does not know his PROLOG or LISP will be as much outdated as he or she who today do not know his or her Hofeldt or von Wright.
The English language is uncomfortable with respect to the word "informatics", though it is creeping into use as those of us who have another mother tongue, have found our national equivalents to that word very useful. "Rechtsinformatik" in German is, however, a somewhat broader term that "informatique jurididique" in French. The aspect that is attractive to Scandinavian users of the word, is that unlike "computers and law" it is not limited to computer technology, but will include telecommunication and other elements of information technology, as well as system development, methods and theory of computer science, etc.
This as an introduction to the notion of "the informatics of public administration." Public administration is governed by law - its institutions are created according to principles of public law, there are rules for the procedure when making individual decisions, development regulation, etc. Information technology has offered itself to public administration as a welcome possibility for increasing efficiency and to tackle new challenges.
It may be maintained that the Scandinavian welfare systems, which embrace the whole population, and presume that government agencies make individual decision with respect to in principle all citizens,[17] would not have been possible without the large data bases containing files on each individual, and decision support programs. It has been jokingly remarked that there is no coincidence that the IBM 360 - series was introduced approximately at the same time as Norway introduced its population-wide social benefit program in 1967: The population of some 4 million individuals fitted into the direct access media of the mainframe computers, and created the base on which further computerisation of public administration has grown. Actually, the co-occurrence in time is incidental; the reform was planned with little knowledge of technology for administrative procedures, and the computer systems were designed at a somewhat late stage in the planning of the reform.[18] But on the introduction, the social benefit system was operational, and today the computer systems are obvious requisites for our social security law.
This development is also significant with respect to the law. Because the public administration is ruled by law, the computerised systems are developed within legal restraints. And the systems themselves are designed to assist in making decisions within the public administration, decisions which are legal by nature.[19] This assistance was perhaps originally one of managing of files as data bases, or making the complex calculations of social benefits, taxes etc when the figures had been decided by case handlers. But the development quite early started to represent elements of legal rules in the programs themselves, and there merged partly or wholly automated systems. A well documented example is that of the Norwegian Housing Aid system:
Fig 3 - Simplified organisation of the Housing Aid System
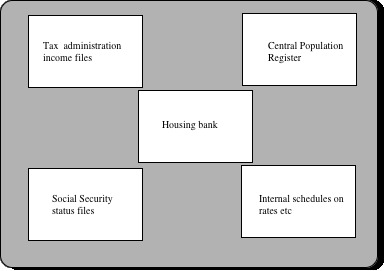
This system became operational as early as 1972. It is written in COBOL, and trundled along on the traditional mainframes. The interesting aspect of the system was its achieved level of automation: The applicant only identified himself or herself by the universal PIN used in Norway, and the system itself collected information from various external data bases, processed these according to rules representing the law basic to the housing aid scheme, and printed out either a form letter with an explanation why the applicant did not qualify for aid, or a postal cheque.
The details of the system, or the law of housing aid, is in our context of little or no interest. Of interest is the fact that this system actually implies the same problems as the more sophisticated problems briefly discussed in the preceding section. The system chart may be reorganised to reflect the more common architecture of a knowledge based system:
Fig 4 - The Housing Aids systems as a knowledge based system
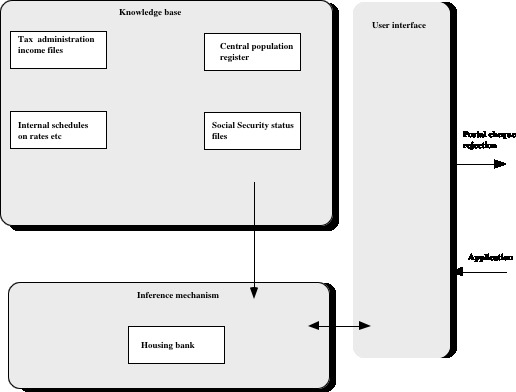
The problem of representing legal knowledge is, consequently, not only one which is stimulating in the perspective of legal philosophy or the theory of norms. It is also a highly practical matter. The computer systems actually represent a code in two meanings of that word: Both programs and law. The transformation of the law as contained in statutes and regulations into source code is obviously not a trivial task. It is also obviously closely related with the drafting of regulations, presuming some of the same legal expertise - at the same time as the draftsman obviously has to know the semantics of the high level programming language as well as the traditional draftsman has to know his or her regulatory prose.
Without probing too deeply into the legal issues involved, three of them may be highlighted.
(1) Data quality. The development and augmented the use of computerised systems implies use of pre-recorded information maintained in data bases, increased exchange of data, and more frequent re-use of data collected for one purpose in a new and different context. This is, of course, one of the major policy issues involving data protection. But apart from the data protection angle, there are legal aspects to such developments. The stored data corresponds to some basic definition - if imported into another system, this implies a proposition that the basic definition of the legal criterion are identical. Also, one should make sure that the data in other aspects are appropriate in the new context - for instance, that data collected from different sources have the same currency, and do not indicate the situation at too widely dispersed moments along the life line of the person in question, or that different verification procedures make the data quality incompatible.
(2) Legality control. The computer program should mirror the law to the extent that the legal rules are represented. Amendments which are necessary for programming, should rest with the necessary authority in the form of a delegation of regulatory power. From examination of samples of the source code of Norwegian systems, we know that occasional errors occur.[20] The basic regulations may be mis-interpreted by the system developers, and the programs are not always corrected as a result for amendments of the regulations. There has to be methods or practices for the co-operation of lawyers in the system development team, and for "translating" regulations into programs.
(3) Appeal and control. It may also be queried whether the traditional appeal system is appropriate in this context. This system rests on an individual challenging a decision, which is then reviewed by higher administrative authority, or a tribunal or a court. But the risks involved in erroneous systems are not limited to wrongs in an individual case; the systems represent an aggregated risk for mis-management of public funds, and a duty with respect to the traditional rule of law to make sufficiently sure that they function according to the law. Perhaps there ought to be review or audit systems which have the authority, tools and knowledge to examine the systems.
The Nordic Council discussed in February 1991[21] a proposal for action with respect to these issues. Though the proposal was turned down by the smallest margin, there was - it would seem - unanimous approval for pursuing the issues at a national level. And in order to address the same problems, an initiative has been taken at the University of Oslo to create a new Master's program.
One will appreciate that the issue of decisions systems in public administration is one more example where the law has fused with the technology to become a integrated subject for research and study. But there are other areas of legal information technology which do not have such an intimate relationship.
An example is the design and analysis of information retrieval systems, especially text retrieval. It can - and should - be argued that there are overlaps between the study of legal research and computerised information systems. And as such systems should be designed to assist and improve the work of lawyers, a deep understanding of this work is presumed.
However, there are issues which are important for the performance of text retrieval systems, but which are only related to law by the fact that legal information services are based on text retrieval. This would concern matching algoithms, optimal data structures for retrieval and updating methods for the integration of hyperlink-functions, etc. Actually, it is to some extent amazing that the development of text retrieval to such a large extent has been stimulated by legal research and actually carried out by lawyers. This is no less true for Canada - there are numerous examples: The innovating design of the bi-lingual thesaurus of the late Quebec DATUM system; the pioneering work by Hugh Lawford of Kingston, on which the current QL - system is built, and which originally was the software which the information service of West Publishing Company, WESTLAW, employed; to the current bold and creative work carried out at the University of British Columbia within their FLAIR program.
This has also been a keen interest by researchers in my own institution, the Norwegian Research Centre for Computers and Law. The NRCCL is a department of the Faculty of Law, and in Norway the study of law lasts in principle five years, ending with the degree of a candidate of law. Though there is some room for flexibility, the study is monolithic. The resources of the faculty are strained by the approximately 6,000 students currently studying law.
The faculty has been generous towards the NRCCL. But it should be realised that the research in text retrieval methods seems rather far removed from the teaching needs of the faculty. And it may be a paradox that perhaps the only university institution teaching text retrieval, does this within an optional course to the law degree, the candidates of which do not see programming or system design as an obvious alternative to their future careers.
Mention is made of this to clarify the policy issue facing the NRCCL. If the institution was to maintain a research activity of an acceptable quality, it needed, so to say, another leg on which to rest its credibility within the university environment. The NRCCL actively pursued alternatives, and found willing and interested partners at the other faculties of the University of Oslo. From this cooperation emerged the plan for a new inter-faculty Master's degree. The principles undelying such a degree are indicated by the diagram below:
Fig 5 - Structure of the new Master's degree
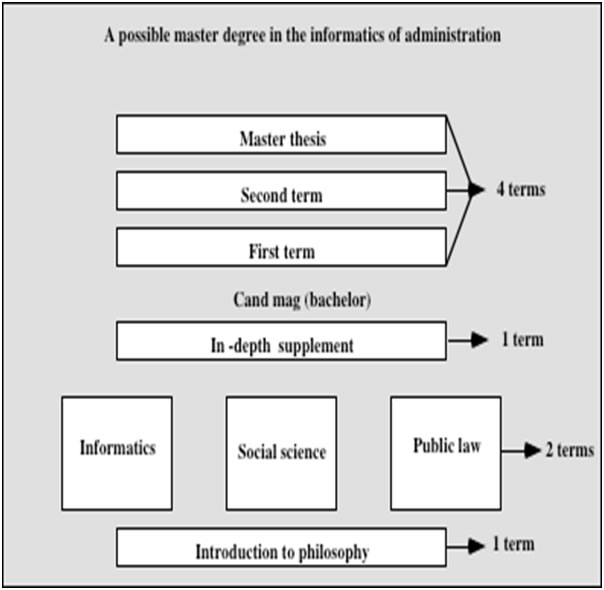
The idea is that students achieve a composite bachelor's degree based on exams from three different general subjects - social science, informatics and law. The informatics may be exams from the computer science department, or from the more recent department of humanistic informatics, emphasising knowledge based technology, logic and linguistics. The social science exam may be one of several - political science or sociology being two prime alternatives. The law exam would typically be the public law exam. In one of these areas, a special in-depth supplemental exam has to be passed. On this basis, the students may apply to the Master's program, which will have a duration of two years, most of it taken up by the work on a thesis, but starting off with a compulsory term in legal informatics. It is suggested there will be two main areas of study within this program: one covering issues related to the management of large data bases, including text bases; the other dealing with logic, the theory of norms, and knowledge representation.
The proposal was accepted by the University governing body in 1991 - plan for the implementation of the program was developed. This has quite recently been accepted. Part of this plan is that the administration of the program was made the responsibility of the NRCCL, which in this way has achieved its second legal balancing the traditional law with something closer related to computers.
The background of this proposal is found in the pragmatic of the national, Norwegian situation. Nevertheless its is offered as a pointer for what may happen in the next decade. Within this program, computers and law have found a new balance, emphasising the inter-disciplinary nature of the field, and being placed in the centre of a university study - no longer an accessory of the conventional law study.
Above, the focus has perhaps been on legal information technology rather than the law of information technology. But let us finally turn to the law, that area which has different names: "computer law" or "information law".
The term "information law" has the advantage that it begs the question: In what way does law govern information? If the term "information" is used in a technical sense, it is in computer science typically defined as something different from data, usually as knowledge. This creates a triad of terms, starting with a sign, which alone or combined with other signs constitute data, which is converted into knowledge only if communicated to and understood by a person. This is, however, only a characterisation. If it should be refined into a definition, one would have further discussed a number of aspects - for instance what is meant by "understanding".
But for our purposes, the main point is to draw the attention to the fact that in this sense, information always has to be in the minds of persons, it is a term related to other familiar terms like "thought" or "idea". And our thoughts are not subject to law - the frightening notion of the Thought Police is one aspect of the tyranny of George Orwell's novel 1984.[22]
Nevertheless, a large number of legal rules applies more indirectly to information. Discussing this, one may suggest that there are two main types of criteria used by the law to deal with information: One functional and one substantial. These are summaries in the table below:
Fig 6 - Criteria used for regulating information

The different categories can briefly be exemplified.
The functional purspective. Rules on creation abound. One important area, for instance is copyright law which assigs the exclusive right to exploit a work to the originator, the person creating the work. Rules of communication include both rules on confidentiality and the freedom of information legislation. Rules on storage would involve not only the data protection and computer security regulations, but also the legislation concerning the storage of accounts and related material for auditing, tax purposes etc. Even the law on libraries can be seen as a form of law governing the storage of information (or - in our characterisation of this concept - its representations, potential information or data). Rules on processing would include the law of evidence - what sort of information should be allowed to be passed on to a jury or the bench - as well as other regulations on procedures before courts, administrative bodies etc.
The substantial perspective. Rules relating to the content of information also abound - data protection legislation concerns personal data. There are restrictions related to blasphemy, slander, pornography, as well as regulations governing advertisements for alcoholic beverages, tobacco or medicines. The form may be relevant - the same information may be conveyed by a painting or a photograph, but different regulations apply. This seems rather obvious. Less obvious is using the structure of the representation of information as a criterion. But, for instance, in defining the type of personal data systems subject to data protection legislation one often refers to its structure - cf the introductory example on the retrievability criterion in US and Norwegian law. Also the medium may be relevant - this is something different from both form and structure: Traditionally one distinguishes between the printed media and telemedia, but these may be subdivided. There are often special privileges and obligations for the publication of daily newspapers; broadcasting is typically subject to licensing schemes; telecommunication is closely regulated both with respect to the physical infrastructure and telecommunication services. The recent directives of the European Community to secure competition within this area may be an exponent of these regulations.
This bird's eye view is sketched in order to justify a conclusion: Information law is very wide indeed. It will not be appropriate to include all these aspects within computers and law. On the other hand, all these regulations concern in one way of the other information, and this implies that information technology has a potential impact on all these regulations.
To some extent such impact will take by suprprise the practitioners concerned by the regulations in question. They will call in the specialists - not the specialists within their own legal discipline, but the specialist in technological impact those working with computers and law. And looking back on the history of the NRCCL there are numerous examples of such alarms, resulting in reports on subjects as different as computer related crime, taxation of computer programs, newspaper data bases and the employment contract of journalists, liability for expert systems, accounting law and machine readable records, digitalised maps and their protection, etc.
This will probably still be the case in the future - some of the efforts will be problem-driven, the agenda set by public policy and regulatory reform rather than by research programs. But these are short-term activities - when the impact analysis is completed, we may turn the result back to the lawyers concerned. These issues result in some sort of temporary information law. As the infection of high technology spreads throughout the body of society, temperature rises as different areas, the specialist is called in, and as the fever is brought down, things return to normal.
But there are issues arising that do not have a fallback team of experts. The typical example is data protection - though related to the traditional concern of privacy, this law has become a new area of research and study. There are also other examples. Looking to the situation at the NRCCL, I might suggest three areas which will remain priorities for information law over the next decade: Data protection, telecommunication law, and intellectual property protection of computer programs, data bases, and integrated circuits. I admit this suggestion lacks in originality, but this does perhaps lend it some more credibility. One should also appreciate that they are focal points rather than circumscribed areas.
Telecommunication law includes broadcasting law, which presumes some understanding of media law in general, advertisement law, etc. Taking hold of any of these focal points, some of the surrounding fabric of the legal system will follow - the higher one's ambitions, the more of the fabric will be lifted. And in addition, there will - of course - be an increasing number of issues which due to the pragmatic of future technological development will need the assistance of an information lawyer for impact analysis.
In this presentation, I have attempted to address the question of what development we should expect - and perhaps promote - for the next decade. The conclusions have given three general indications:
Firstly, there will be an emphasis on the interrelationship between knowledge based systems and legal philosophy or jurisprudence.
Secondly, there will be a need to create a university study centred on the combination of computers and law, both to justify research in legal information technology, and to meet the increasing needs for this joint expertise, especially in system development for public administration.
Finally, there will also in the future be a need for impact studies within different areas of the law which are strained under the pressure of the introduction of new information technology, but some subjects will be seen as a core of the new discipline of information law - and it is suggested that these will be data protection, telecommunication law, and the intellectual property protection of computer programs, data bases, and integrated circuits.
[1] Paper commissioned for the opening of the international conference "Computer and Law: State of Art and Current Issues" organised in Montreal 30.9.-3.10.1992 by Association quebecoise pour le developpement de l'informatique juridique (AQDIJ) and L'Association pour le developpement de l'informatique juridique (ADIJ, France).
[*] Norwegian research Centre for Computers and Law, Faculty of Law, University of Oslo, Niels Juels gate 16, N-0272 OSLO - Norway.
[2] Cf his compilation Material and Cases on Computers and Law (1st edition) Boston 1968 (privately published).
[3] For instance represented by his reader Computers and the Law: An Introductory Handbook, Commerce Clearing House, Chicago 1969 (2nd edition).
[4] "Les sciences juridique devant l'automation"; Cybernetica 1960:22-40, 142-160) - actually a very early suggestion for employing knowledge based systems for legal decision making.
[5] Tapper's, Computers and the Law (Weidenfeld and Nocholson, London) (first edition was published in 1973), remain a standard work within the field. Tapper was originally inspired by the early efforts of Horty to do research in case law retrieval, conducting the first controlled experiments.
[6] Institut de recherces et d'etudes puor le traitement de l'information juridique at the Universite de Montpellier. In spite of its name, which reveals the original interest for legal information systems, the IRETIJ is offering courses in the law of information technology, also on a post-graduate level.
[7] Professor Catala has now moved to Paris.
[8] The Norwegian Research Centre for Computers and Law was founded in 1970 by professor Knut S Selmer and myself, and also is an example of this type of institution.
[9] Mr. Skelly was as early as 1970 appointed by the Department of Justice as a special "jurimetrics adviser", and has had a long career in that department. Together with Mr. Morgan he developed what must have been one of the very first legislative information systems for the province of Mantioba. Mr. Morgan returned to United Kingdom where he became Computer Development Officer to the House of Lords, and wrote extensively on computer law, cf for instance Richard Morgan and Graham Stedman Computer Contracts (3rd edition). Longman, London 1987, Richard Morgen was, by the way, my first teach of computers and law at a Council of Europe symposium of 1971.
[10] Who was one of the persons behind the Quebec system DATUM (1971-79), and whose extensive production has been influential in both the two areas of computers and law.
[11] Computing Law Liber Stockholm 1977.
[12] Cf Kevin D. Ashley Medelling Legal Argument: Reasoning with cases and Hypotheticals, Artificial Intelligence and Legal Reasoning series, MIT Press, Bradford Books, Cambridge (Massachusetts) 1990. The argument will also be sketched in a forthcoming review of his book in the new journal of AI and the Law.
[13] The original theory was put forward in Nils Kristian Sundby Om normer, Norwegian University press, Oslo 1974. It has been elaborated by Torstein Eckhoff and Nils Kristian Sundby in Rettssystemer, Tano, Oslo 1991 (2nd edition).
[14] Cf for instance Johannes Hansen Simulation and automation of legal decision CompLex 6/86, Tano, Oslo 1986 with further references to the work at the NRCCL.
[15] One of the first presentations of a computerised model based on he work of Sundby may be found in John Bing "Legal Norms, Discretionary Rules and Computer Programs", Bryan Niblett (ed) Computer Science and Law, Cambridge University Press, Cambridge 1980:119-136. This is the proceedings of the Swansea seminar in 1979, by many seen as the first international seminar devoted to AI and the Law. Sundby should have taken part in that seminar, and it was with regret that my presentation would have to be dedicated to his memory.
[16] See for instance R. Dwarkin "The Model of Rules", 35 University of Chicago Law Review, 1967:14.
[17] Actually, whether the system is based on citizenship or domicile differs between the Nordic countries.
[18] Cf Dag Wiese Schartum The introduction of computers in the Norwegian local insurance offices, CompLex 9/87, Norwegian University Press, Oslo 1967.
[19] There are differences between jurisdictions as to what extent such decisions are seen to concern fact finding or law. In the Nordic countries the legal nature of the decision are emphasised, and the general and special law of public administration is an important part of education.
[20] Cf Dag Wiese Schartum Eg rettslig underokelse av tre edb-systemer i offentlig forvalning, CompLex 1/89, Tano, Oslo 1989.
[21] Session in Copenhagen, cf Lov & data 29/1992:7.
[22] Harcourt, Brace and Company, London 1949.
AustLII:
Copyright Policy
|
Disclaimers
|
Privacy Policy
|
Feedback
URL: http://www.austlii.edu.au/au/journals/JlLawInfoSci/1993/2.html