
Journal of Law, Information and Science

|
|
Home
| Databases
| WorldLII
| Search
| Feedback
Journal of Law, Information and Science |
|
by
M.G.K. Einerhand[*] and J.S. Svensson[*]
This article offers an example of an expert system used in the administrative law area. The authors report on the design and testing of ExpertiSZe, an expert system involving the determination of benefits under the Dutch Unemployment Act. The researchers found that ExpertiSZe produced results which correlated highly with actual decisons mady by administrative departments. The article goes on to explain the potential benefit to lawyers, economists, and policy makers which can be derived from the use of such expert systems to analyse the likely impact of legislation.
___________________________
Social security expenditure in the Western European countries accounts for a quarter to a third of the GDP. The Netherlands' spending on social security for the last 10 years has been the highest in the European Community (over 30%) while France, Belgium, Denmark and Germany all spend more than 25% (the European Community avarage). Policy-making in this field therefore can have great direct or indirect effects on purchasing power, poverty, tax burden, and in more general terms the economic competitive edge a country has. During the last 10 years many efforts were made to restrict the growth of social security in the Netherlands. As a percentage of the GNP, expenditure now is at the same level as in 1980, after increasing somewhat due to the recession in the beginning of the eighties. Scenarios based on demographic forecasts, and assumptions on labour force participation and employment however show that the aging of the population will create a continuous strain on social security budgets [SZW,1991].
All social security spending is based on legislation, which determines elegibility, duration and level of benefits. In the policy-making process information is needed to prepare this legislation and to evaluate its results.
Since the legislative body must of necessity make many factual judgments, it must have ready access to information and advice. However, this must take the form not merely of recommendations for action, but of factual information on the objective consequences of the alternatives that are before the legislative body [Simon,1976].
The role of automated tools in providing the information needed at present is relatively limited in the Netherlands. In the proces of preparing legislation juridical information is available from databases on existing legislation and case law (both national and international). Socio-economic consequences of new legislation proposals are estimated by means of simulations, in which mostly macro- or mesomodels are used.
One of the fields which might lead to the increased use of automated tools in the policy preparation process is Artificial Intelligence. The emergence of artificial intelligence techniques will make it possible to use and analyse data in ways which were unthinkable before. In a research project, the University of Twente and the Ministry of Social Affairs and Employment in the Netherlands investigated the new possibilities that arise from the developments in artificial intelligence. This project has led to the development of the expertsystem named ExpertiSZe, of which we will describe some aspects in this article.
ExpertiSZe combines, in a rather obvious and simple way several tools for analysing (proposed) legislation. It is especially focussed on the use of the expert system approach in the evaluation of different alternative law proposals.
The complete ExpertiSZe application consists of three modules: a consultation module, a simulation module and a consistency module. These modules are intended to evaluate legislation in three different ways.
The first module, the consultation module, provides the facilities that are common to most expert systems. Its main purpose is to determine the impact of legislation on specific cases (when given information about a beneficiary X with characteristics x1, x2 .. xn, it is able to determine the entitlement to, and the amount and duration of a benefit). Furthermore the consultation module provides possibilities to get insight in the way these results are reached in the form of typical expert system functions like Why and How.
The other two modules of the ExpertiSZe system provide more advanced applications of the expert system techniques. The (proposed) legislation can be checked on redundancies, logical coherence and on omissions within the framework of the act. Furthermore the consistency module provides tools to generate (theoretical) cases to establish whether the outcome of the (proposed) legislation coincides with the intended results of the legislation. The simulation module is used to determine socio-economic effects of legislation by applying an act to a set of cases (e.g. a random sample drawn from the Dutch population).
In order to provide these possibilities all three modules make use of models of legislation (knowledge bases). These models, which are interchangable between the different modules are developed in a knowledge representation language (KRL). This KRL allows an almost one-to-one (isomorphic) representation of the law, which ensures that there is a very large correspondence between the model and the actual legislative texts.
In this article we will disregard the consultation and consistency modules of ExpertiSZe, as well as the details of our knowledge representation language. Instead, we focuss solely on the simulation module and its possibilities. In order to do this we will first discuss some relevant aspects of simulation in the context of policy analyses and explain our approach of knowledge based micro-simulation.
In the proces of policy preparation there is clearly a need for information on the socio-economic effects of proposed legislation. In the Netherlands these socio-economic effects are often determined through the use of macro- and meso models of the legislation.
In less complex situations these models produce satisfying results. In some cases however, the meso and macro models can be shown to be insufficient. This is especially so when the information at the meso and macro level is limited in its dimensions (two or three-way tables), and assumptions have to be introduced to combine the available information. This is for instance the case in the following example.
In the Dutch unemployment act the duration of the benefit depends on the employment history of the beneficiary. The rules that describe the computation of this employment history are rather complex. Suppose we consider to add the rule that raising a child in the age group from 12 to 16 is to be considered as partial employment. We might then consider the following macro-level questions:
- How many people will benefit from this rule;
- What will be the avarage gain in the duration of the benefit;
- What will be the yearly costs of this measure;
We might however also want to know some meso-information like:
- What will be the avarage gain in duration for women; or even
- What will be the avarage gain in duration for divorced or widowed men over fifty-seven.
In these kinds of cases the use of a macro or meso approach will demand many assumptions in order to combine the necessary information. These assumptions may lead to unreliable results of such models.
For several years, it has been known that (part of) the problems that are related to the use of meso and macro models may be solved using a more detailed simulation technique called micro-simulation (Orcutt et al., 1976) .
Microsimulation is an approach based on the analysis of individual micro-units (for example individual persons, households or companies) instead of groups. Databases on micro-units, for example the Socio-Economic Panel (SEP), often contain hundreds of variables. These kinds of databases can be regarded as tables of hundredfold dimensions. No assumptions are needed to combine two or more variables because the two variables are measured at the basic level.
Based on such micro-data, it is possible to determine the impact of economic and social policies on each individual micro-unit concerned [Merz,1991]. By aggregating these individual results we can estimate the macro and meso of a proposed change in policy, and analyse distributional effects.
The main advantages of micro-simulation can be summarised as follows:
- Micro-models estimate the effects of policy-measures at a basic level. Because many social security and taxation laws are prescriptions to calculate benefits or taxes at the individual level, there is a close resemblance between model and law (or proposed law). Complicated institutional regulations can be modelled in a relatively detailed way, i.e. in the degree of detailedness the policy maker needs in his daily work (Hoschka,1986].
- All information on the initial status of the individual micro-units and therefore all (implicit) relationships between the variables on a micro-level can be used in the analysis. In macro-models only the relationships which are explicitly mentioned in the model will be used. This means that in micro-models less assumptions are needed.
- Micro-results can be aggregated any way one likes. If data permit results can be presented by age, sex ,region, effects on the income distribution etc.
Furthermore because of the relatively detailed way in which policy proposals are modelled it is possible to gain insight into the exact mechanisms which determine the measured effects.
However, there are also several disadvantages related to the use of micro-simulation. These disadvantages are:
- Behavioral relations in micro-models are often not well founded theoretically and/or empirically. Consequently they are seldom used, and only first-order effects are calculated.
- The quality of the data is often a restricting factor.
- The development of micro-models is time-consuming.
- Large micro-models tend to grow very complex and are hard to "control". In practice therefore many micro-simulation models do not describe legislation in all detail, but focuss on the most important items of legislation.
Especially the last problem can be regarded as a disadvantage in the micro-simulation approach. In the context of our demand for detailed information on the socio-economic effects of legislation, it reduces the added value of traditional micro-simulation over the meso and macro models that are already in use. Micro-simulation would be far more interesting if we would be able to make more detailed models, which remain understandable and workable.
Here we found an opportunity for our ExpertiSZe approach. The knowledge based models which we developed for use in the consultation and consistency modules, are in fact the kind of modules which we would like to use in micro-simulation. These models contain complete and detailed representations of proposed and/or existing law.
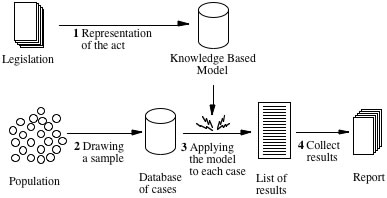
We therefore developed a method of using ExpertiSZe knowledge bases as micro-simulation models. This method of what we will call Knowledge Based Micro Simulation, or KBMS, is in fact very simple. The method consists of four steps:
1. Representation of the legislation in a knowledge base;
2. Data collection ( a sample of the population or (potential) beneficiaries);
3. Application of the model to the cases in the database to produce the desired results;
4. Aggregation of the results in parameters that may be used in the policy preparation process.
Figure 1: The principle of knowledge based micro-simulation
As discussed before, the knowledge based micro-simulation method was developed in order to determine the effects of legislation. The question that should be answered is therefore: What is the value of this knowledge based microsimulation approach in the context of policy analysis?
In order to answer that question, two subquestions should be addressed:
1. How accurate are the results that can be reached through the use of KBMS?
2. How does KBMS compare with other methods of policy analysis, especialy "traditional" microsimulation; What is the added value of the “KB” in KBMS?
In the next sections we will discuss the results of three experiments that were set up to give an answer to these questions. These three experiments concern one domain of legislation: the social security legislation based on the Dutch National Assistance Act, and especialy the "Besluit Landelijke Normeringen" (decree on national standardization) which determines the level of the benefit for each individual beneficiary.
Based on this decree of national standardisation, we have developed a knowledge based model (the so called BLN-model). This BLN-model contains 141 parameters, of which 45 are input parameters and 96 are output and intermediate parameters.
Section 3 discusses the results of two experiments which were performed to determine the accuracy of KBMS. Section 4 concerns an experiment in which KBMS was compared with traditional microsimulation.
As discussed, our first aim in determining the value of KBMS should be an assessment of the accuracy of the results of KBMS as compared to the actual decisions. Our research question is:
Does knowledge based micro simulation lead to results that correspond with the actual results of the legislation in the field of social security?
The answer to this question is not as obvious as it might seem. Although many people regard social security legislation as a set of rules that give an exact prescription what is to be done when deciding on an individual benefit, there are others who argue that the actual legislation might have in practice very little meaning.
[..] those "paper rules", "pseudo rules", "accepted rules", or "verbally formulated rules" were of no use in assisting the lawyer in the important job of predicting judicial decisions [Susskind, 1986]
Moreover, there are some known reasons that might lead a civil servant to deliberately deviate from these existing rules. These reasons are for instance:
- applicability of case law to a certain decision,
- the applicability (within the framework of the Act) of special (local) rules on the administrative level,
- the observation by the civil servants that the official rules will not lead to the intended results of the act (in a specific case).
The question of the actual correspondence between model and practice should therefore be established. This led to the two experiments, that we will discuss in the subsections 3.1 and 3.2.
The first experiment designed to assess the accuracy of the BLN-model, is a comparision between the results of our model and the actual decisions made by a local social security office (in the Netherlands’ situation this is the Gemeentelijke Sociale Dienst, generally abreviated as GSD).
A random sample of 101 dossiers was drawn from the population of beneficiaries of this GSD. For each beneficiary in this sample we administered both, the relevant ‘input’ characteristics that were needed to operate our BLN-model, and the actual benefit as determined by the civil servant of the GSD.
Based on these input characteristicsused we used the BLN-model to generate 101 model-benefits. These model-benefits then were compared with the actual benefits, as determined by the GSD.
After a first experimental round in which several errors in data and model were corrected, the second round of this experiment produces following results:
Of the 101 cases 85 decisions of the municipality are exactly reproduced by the model (see table 1). Comparing the aggregated results we found that the distribution of the model-benefit was very close to the distribution of the real benefits (table 2).
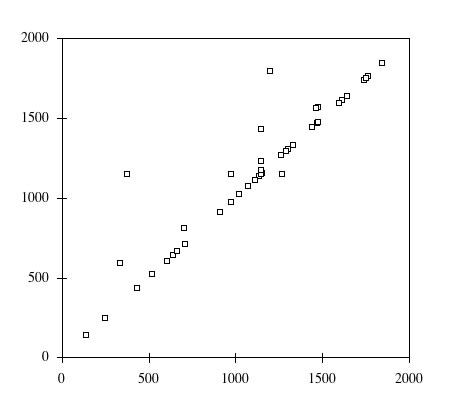
When applying linear regression, a correlation coëfficient of 0.95 was found (figure 2). The equation of the least squares regression line is: M = 128.3 + .92R (in which M is the model decision and R is the real decision by the GSD) .
Table 1: Discrepancies between model and actual benefit
Discrepancy frequency
No discrepancy 85
Discrepancy of
- less than ƒ. 1,- 4
- between ƒ. 1,- and ƒ. 50,- 2
- between ƒ. 50,- tot ƒ. 100,- 2
- between ƒ. 100,- tot ƒ. 250,- 4
- between ƒ. 250,- tot ƒ. 500,- 2
- more than ƒ. 500,- 2
Table 2: Distribution of model-benefit, real benefit and difference
Model Actual Difference
mean 1272.65 1248.77 - 23.88
st. deviation 340.77 354.69 106.58
maximum 1842.54 1917.54 1034.85
minimum 143.03 180.23 -772.11
Figure 2 Model benefits (vertical) as a function of the real benefit (horizontal); (n = 101)
Although it may seem logical to base KBMS solely on the reliable administrative data, this is not always possible or desired. Some serious problems related to the use of administrative data are:
- the impossibility of determining the inflow effects of new legislation, because administrative data only refer to present cases.
- the possible lack of important information in administrative data (e.g. the lack of variables that are needed to compute the effects of a new legislation proposal).
- a lack of insight in some important aspects of social security, for example fraud and non-take-up (because administrative data are through their nature relatively consistent).
A more practical argument against the use of administrative data is that data-collection is very time-consuming and expensive.
It was therefore found nescessary to perform another experiment to validate the KBMS-method using survey data. In this second validation experiment we used data of the Socio-Economic Panel (SEP) data. The SEP is a relatively large survey (N=14,055, around 5000 households) covering the total Netherlands’ population. It contains detailed information on income, sources of income, living arrangements, housing, cost of housing etc.
For our analyses 353 persons were selected who receive benefits on the basis of the National Assistance Act. Because of the limited information available in the survey data, we used a reduced BLN-model (based on only 20 variables) to compute the model-benefits. Again these benefits were compared with the real benefits which were also provided by the survey data.
As a result of applying the reduced BLN-model to the data from Socio-Economic Panel, initially, 71% of the cases were calculated correctly (correlation .75). Using a correction of the input data, based on the assumption of inconsistencies in the income-data, it was possible to increase this percentage of hits[1] to 80 % (correlation .89). One of the factors creating mismatches between calculated and real benefits is for example labour income mentioned in the survey by the beneficiaries which is not known to the municipality.
Figure 3 shows the resulting match between calculated and real benefit for 353 cases. One must be aware that the graph suggests larger differences, because many points on the diagonal (often 20 or 30) are represented by only one point in the graph.
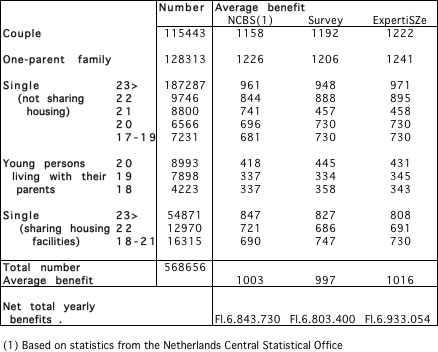
For an insight in the correspondence on the aggregated level we have presented table 3. In this table some aggregated result of both the real benefits and the model-benefits are computed, and are compared with the actual information on the social security benefits by the Netherlands by the Netherlands’ Central Statistical Office.
Figure 3 Match between the real and the calculated benefit
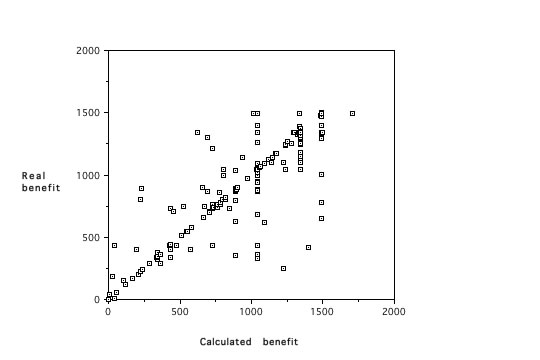
Table 3: Average monthly benefit by benefit category
From the results of both experiments, it is concluded that the experiments indicate that our model leads to results that highly correspond with actual decisions by the GSD. The individual differences that are found to be acceptable and do not lead to significant differences in the computed aggregated parameters. We therefore accept that our model is valid.
With regard to the differences found in the first experiment, the following causes were found to be of some importance:
1) The use of discretionary powers by the municipality. This especially accounts for the three largest differences in which the GSD did not apply the normal rules because of the special situation of the beneficiaries (two persons living in a bed&breakfast place, one being partly hospitalized).
2) Incompleteness of the model. The model fails to cover some parts of the legislation (e.g. penalty deductions on the benefits).
3) The re-interpretation of cases by the GSD. In some cases the data delivered by the beneficiairy are not accepted as fact (e.g. A man living together with his german girlfriend is denied the benefit for a couple because the girlfriend is considered to be a tourist).
4) Small computational errors made by the municipality (e.g. in rounding off).
In the second experiment these problems, of course, also played some role. However, although it was not possible to analyse the exact cause of the differences in this experiment, it is assumed that the dicrepancies found in that experiment, were largely the result of the lack of some relevant input variables (which lead to the necessary reduction of our model), and some degree of data-error.
When assessing the value of a new technique, it seems a logical step to compare the new technique with other, already existing techniques, in order to determine the added value.
In our case, this could mean the comparision of KBMS with all kinds of other socio-economic analysing techniques on the different macro-, meso- and micro-levels. Because of the very good performance of our model, as shown especially in the experiment on administrative data, it is clear to us that, regarding the accuracy of our model, the KBMS approach outperforms both meso and macro approaches. And in the context of perfect administrative data, the KBMS-model is also believed to be more accurate than the simpler traditional micro-simulation models.
In the context of imperfect data, as was the case in our last experiment, we can however dispute the advantages of KBMS. The question that may be asked is:
What is the added value of very accurate KBMS-models, when using imperfect input data?
To answer this question, we conducted a third experiment. Based on the SEP data, we compared the KBMS-model with a traditional microsimulationmodel, that was based on only eleven input parameters.
Table 3 shows the correlations between the decision by the GSD, ExpertiSZe and the traditional model. The correlation between the actual benefit and the benefit calculated by the "traditional" microsimulation model is 0.80. Comparing the performance of ExpertiSZe with the traditionalmicrosimulation model the overall gain in performance is relatively limited (about 0.1).
Table 3: Correlations between the KBMS-results, the traditional microsimulationmodel and the actual benefit.
Actual KBMS Micromodel
Actual decision 1.00
KBMS 0.89 1.00
Micromodel 0.80 0.90 1.00
Results based on the SEP datacollection
These results show us what was already expected: in the context of imperfect data, the added value of the KBMS-approach, as far as accuracy is concerned, is relatively limited. It is stressed that, in order to profit from the accuracy of knowledge based simulation model, input-data should also be of high quality.
Microsimulation is a useful tool in situations where the act to be analysed is complicated and data at a meso-level are inadequate to describe the interrelations between variables. One of the main advantages is the reduction of assumptions within the models, because these relations are implicit in the dataset at a micro-level. The extra added value of knowledge based microsimulation is the completeness and accuracy of the model. One can be sure that all the different intricacies of the Act under study are automatically reproduced in the model. If data permit, this generates a good insight even into the most detailed effects.
In this article we validated the ExpertiSZe model at the basic level by confronting decisions made by the GSD with decisions generated by ExpertiSZe. This test was successful and necessary to gain confidence in modelperformance.
Experiments on the SEP data showed however, that a main problem in the use of the full ExpertiSZe model is adequate data.
In order to develop the models potential to the utmost, data should allways be "as good" as the model. In order to develop this idea further, we are now working on a special data-collection project for the purpose of KBMS.
But even if it were impossible to generate better data, we feel confident that the knowledge based approach, as used in ExpertiSZe, is a good step towards better and more accurate microsimulation models. Using survey data the increase in accuracy might not be overwhelming, but still there is an increase.
Moreover, in the ExpertiSZe context, the KBMS model has an added value because of its use in both socio-economic and legal policy-making. This is of great importance because this way the economist is provided with a full model of the Act. This means that the two policy-making domains, legal and economic, are much more integrated, and that the economist does not have to analyse the proposed law in depth to be able to interpret all the differences with current law and write mathematical models. Problems in interpreting the law can thus be avoided and the effects calculated by socio-economic analists can be more easily discussed with the legal policy-makers (because the legal policy-maker programmed the model). The use of a one-to-one representation of the law makes it possible to link the results of socio-economic analysis directly to the policy-proposals. This gives a better opportunity to make adequate improvements in these proposals.
The authors thank all other participants in the ExpertiSZe project; Especially members of the working party from the Ministry of Social Affairs and Employment: G.J van ‘t Eind, A. Kemps and F. van der Knaap; and our collegues at Twente University: J.G.J. Wassink, P. Kordelaar and P. Klijnstra.
Eind, van 't G.J, J. Sonnemans, M.G.K. Einerhand (1990). Simulationmodels describing the Dutch unemployment insurance. in J.K. Brunner en H.G. Petersen (red). Simulation Models in Tax and Transfer Policy. Giessen, Univ. van Giessen.
Fulpen, H. et al. (1985). Berekend Beleid: Sociale en Culturele Studies-5. 's Gravenhage, Staatsuitgeverij.
Hoschka, P. (1986). Requisite Research on Methods and Tools for Microanalytic Simulation Models. In Orcutt et al. (1986). Microanalytic Simulation Models to support Social and Financial Policy.
Merz, J. (1991). Microsimulation a survey of principles, developments and applications. International Journal of Forecasting, Vol. 7 (1991) pp. 77-104.
Orcutt, G.H., S. Caldwell and R Wertheimer II (1976). Policy exploration through microanalytic simulation. Washington, The Urban Institute.
Orcutt, G.H., J. Merz en H. Quinke (1986). Microanalytic Simulation Models to support Social and Financial Policy. Amsterdam, Elzeviers Science Publishers B.V.
Simon, H.A. (1976). Administrative Behaviour. London, Collier Macmillan Publishers.
Simon, H.A. (1981). The Sciences of the Artificial. Cambridge etc., The MIT Press.
Susskind, R.E. (1986). Expert systems in law: A jurisprudential inquiry. DPhil thesis, Oxford University.
Svensson, J.S. (1993). Kennisgebaseerde microsimulatie, een nieuwe methode voor het bepalen van de sociaal-economische gevolgen van wet- en regelgeving in de sociale zekerheid. Enschede, Universiteit Twente (Phd-thesis).
[*] Ministry of Social Affairs and Employment, P.O. Box 90802, 2509 LV Den Haag, The Netherlands,.
[*] J.S. Svensson, Department of Public Administration, Twente University, P.O. Box 217, 7500 AE Enschede, The Netherlands.
[1] In contrast to our previous experiment, where a hit was defined as a exact correspondence between model and real benefit, in this experiment a hit is defined as a difference of less than 50 guilders. This was decided in order to correct for the fact that the given ‘real benefits’ in the survey data were not always precise.
AustLII:
Copyright Policy
|
Disclaimers
|
Privacy Policy
|
Feedback
URL: http://www.austlii.edu.au/au/journals/JlLawInfoSci/1993/4.html